
AWS re:Invent 2024完全予習ガイド!生成AIとサーバーレスで未来の技術を体験しよう
はじめに
こんにちは!ITの世界で開発や教育に携わっている技術教育者です。毎年冬に開催されるAWSの一大イベント「re:Invent」。世界中の技術者が注目するこのイベントでは、未来のシステム開発を形作る新サービスやアップデートが次々と発表されます。しかし、その膨大な情報量をいきなり追いかけるのは大変ですよね。
この記事は、re:Invent 2024を最大限に楽しむための「予習ガイド」です。特に、近年の技術トレンドの中心である**「生成AI」と「サーバーレス」**に焦点を当てます。この記事を読み終える頃には、あなたもAWSの最新動向の勘所をつかみ、手を動かして簡単なAIアプリケーションを作れるようになっているはずです。技術の波に乗り遅れないよう、一緒に未来の技術を体験し、エンジニアとして新たな成長の一歩を踏み出しましょう!
前提知識の確認
新しいことを学ぶ時、どこから手をつけていいか分からなくなることがありますよね。大丈夫、一歩ずつ進んでいきましょう。
必要な基礎知識
この記事を読み進める上で、以下の知識があるとスムーズです。
- 基本的なIT用語の理解: 「サーバー」「データベース」「API」といった言葉を聞いたことがあるレベルで大丈夫です。もし分からなくても、本文中で都度解説します。
- プログラミングの初歩的な知識: 変数や関数といった基本的な概念を知っていると、コード例の理解が深まります。この記事ではPythonを使いますが、他の言語の経験があれば十分読み解けます。
- クラウドコンピューティングの概要: 「インターネット経由でコンピュータの機能(サーバーやストレージなど)を利用するサービス」という程度の認識があればOKです。
事前に理解しておきたい概念
- AWS (Amazon Web Services): Amazonが提供するクラウドコンピューティングサービスの総称です。世界中で最も広く使われているクラウドプラットフォームで、数百ものサービスを提供しています。
- サーバーレス: サーバーの管理を意識することなくアプリケーションを構築・実行できる考え方です。コードを書くことに集中できるため、開発スピードが飛躍的に向上します。
- 生成AI (Generative AI): テキスト、画像、音楽などを自動で生成する人工知能の一種です。近年、目覚ましい進化を遂げており、多くのサービスに応用されています。
「分からなくても大丈夫」な部分
安心してください。AWSの全てのサービスを知っている必要はありません。この記事で扱うサービス以外は、「そういうものもあるんだな」くらいで大丈夫です。完璧に理解しようとせず、「まずは動かしてみる」という気持ちで進んでいきましょう。途中でつまずいても、それは成長の証です。焦らず、自分のペースで学んでいきましょう。

環境構築:最初の一歩
理論だけでなく、実際に手を動かすことが成長への一番の近道です。ここでは、AWSを操作するための基本的な環境を整えましょう。
開発環境の準備(初心者向け解説)
AWSのサービスを利用するには、まず「AWSアカウント」が必要です。これは、AWSの世界に入るためのパスポートのようなものです。作成は無料で行えますが、クレジットカードの登録が必要です。無料利用枠を超えると料金が発生する可能性があるため、利用状況はこまめに確認しましょう。
アカウント作成後、最初にやるべき最も重要なことはIAMユーザーの作成です。アカウント作成時に作られる「ルートユーザー」は全ての権限を持つため、日常的な作業で使うのは非常に危険です。作業用のIAMユーザーを作成し、必要な権限だけを与えるのがセキュリティの基本です。
必要なツールとインストール方法
次に、自分のPCからAWSを操作するためのツール「AWS Command Line Interface (CLI)」をインストールします。
-
AWS CLIのインストール: お使いのOS(Windows, macOS, Linux)に合わせた公式インストーラーを使ってインストールします。検索エンジンで「AWS CLI install」と調べると、公式のインストールガイドが見つかります。
-
AWS CLIの設定: インストール後、ターミナル(コマンドプロンプト)で以下のコマンドを実行します。
aws configureすると、以下の情報を順番に聞かれます。
AWS Access Key ID: 先ほど作成したIAMユーザーのアクセスキーIDAWS Secret Access Key: IAMユーザーのシークレットアクセスキーDefault region name: 主に利用するAWSリージョン(例:ap-northeast-1は東京リージョンです)Default output format:jsonのままでOKです
これで、あなたのPCからAWSを安全に操作する準備が整いました。
環境構築でつまずきやすいポイント
- 認証情報の間違い:
aws configureで入力するアクセスキーIDやシークレットアクセスキーを間違えると、認証エラーになります。コピー&ペーストする際は、余計な空白が入らないように注意しましょう。 - IAMユーザーの権限不足: CLIでコマンドを実行した際に
AccessDeniedというエラーが出たら、IAMユーザーに必要な権限が付与されていない可能性が高いです。IAMポリシーを見直してみましょう。 - リージョンの選択: AWSのサービスはリージョン(地理的な拠点)ごとに展開されています。東京リージョンで作成したリソースは、他のリージョンからは見えません。作業するリージョンを意識することが重要です。
基本概念の理解
re:Invent 2024で注目すべき技術の核となる考え方を、身近な例えで理解していきましょう。
核となる考え方
今年のトレンドは、間違いなく**「生成AIの民主化」と「サーバーレスのさらなる進化」**です。これまで専門家のものであった高度なAI技術が、サーバーレスという手軽な実行環境と組み合わせることで、誰もが簡単に利用できる時代になりました。この2つの技術を組み合わせることで、アイデアを素早く形にできるのです。
身近な例での説明
-
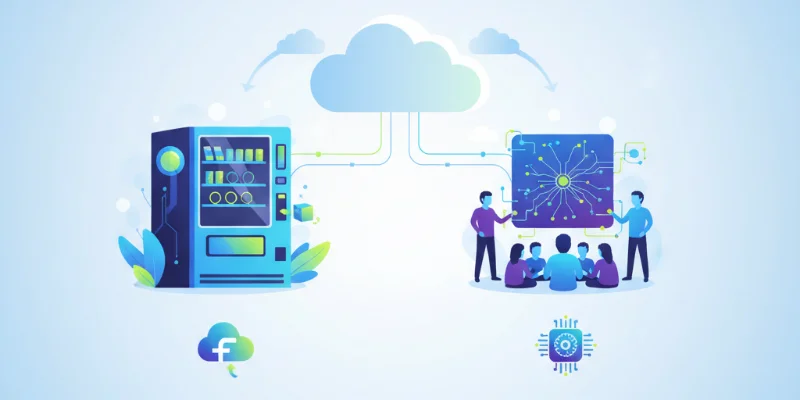
サーバーレス (AWS Lambda): これを「超高性能な自動販売機」と考えてみましょう。普段は待機していて電気代もほとんどかかりませんが、誰かがボタン(リクエスト)を押した時だけ、瞬時に起動して商品(処理結果)を提供します。自分で店舗を構え(サーバーを管理し)、24時間店員を配置する必要がないので、非常に効率的です。
-
生成AI (Amazon Bedrock): これを「様々な専門知識を持つブレーン集団」と考えてみましょう。文章作成のプロ、イラストのプロ、データ分析のプロなど、多様なAIモデル(専門家)が待機しています。あなたは「こういう文章を考えて」「このデータを要約して」と依頼(プロンプト)するだけで、専門家が最適な答えを返してくれます。自分で専門家を育成する必要はありません。
「なぜそうなるのか」の理解
なぜこの組み合わせが強力なのでしょうか? それは、**「必要な時に、必要な能力を、必要なだけ借りる」**というクラウドの思想を究極的に突き詰めた形だからです。
膨大な計算能力が必要なAIモデルを自分で管理するのは非常にコストがかかります。しかし、Bedrockを使えば、APIを呼び出すだけでその能力を利用できます。そして、その呼び出し処理をサーバーレスのLambdaで行うことで、リクエストがあった時だけコンピューティングリソースを消費する、極めて無駄のないシステムが構築できるのです。これにより、個人開発者やスタートアップでも、大企業と同じレベルのAI技術を活用したサービスを低コストで迅速に開発することが可能になりました。
実践編:手を動かして学ぶ
それでは、実際にAWS LambdaとAmazon Bedrockを使って、簡単なAIチャットボットAPIを作成してみましょう。ここでの小さな成功体験が、大きな自信に繋がります。
ステップ1: 基本的な実装
まず、AWS Lambda関数を作成します。これは、特定のイベント(今回はAPI呼び出し)に応じて実行されるコードの塊です。
- AWSマネジメントコンソールにログインし、Lambdaのサービスページを開きます。
- 「関数の作成」をクリックします。
- 「一から作成」を選択し、以下の情報を入力します。
- 関数名:
myAiChatbotFunction - ランタイム:
Python 3.11(または新しいバージョン) - アーキテクチャ:
x86_64
- 関数名:
- 「関数の作成」をクリックします。
作成された関数のコードエディタに、以下のコードを貼り付けます。これは、呼び出されると簡単なメッセージを返すだけのシンプルな関数です。
import json
def lambda_handler(event, context):
# TODO implement
return {
'statusCode': 200,
'body': json.dumps('Hello from my first Lambda function!')
}右上の「Deploy」ボタンで変更を保存し、「Test」タブでテストイベントを作成して実行してみましょう。成功すると、'Hello from my first Lambda function!'というメッセージが表示されるはずです。これがサーバーレスの第一歩です!
ステップ2: 機能の拡張
次に、このLambda関数からAmazon Bedrockを呼び出して、生成AIの力を借りてみましょう。Amazon Bedrockは様々なAIモデルを利用できるサービスです。今回は、Anthropic社の「Claude」モデルを使ってみます。
まず、Lambda関数がBedrockを呼び出す権限を付与する必要があります。
- Lambda関数の「設定」タブ > 「アクセス権限」を開きます。
- 実行ロール名をクリックしてIAMの管理画面に移動します。
- 「許可を追加」 > 「ポリシーをアタッチ」を選択します。
AmazonBedrockFullAccessというポリシーを検索してチェックを入れ、アタッチします。(本番環境ではより限定的な権限にしましょう)
次に、Lambdaのコードを以下のように書き換えます。AWSのサービスをPythonから操作するためのライブラリboto3を使います。
import json
import boto3
# Bedrockクライアントの初期化
bedrock_runtime = boto3.client('bedrock-runtime', region_name='us-east-1')
def lambda_handler(event, context):
# ユーザーからの入力を受け取る(今回は固定)
user_prompt = "AWS re:Inventについて30字程度で教えてください。"
# Bedrockに渡すリクエストボディを作成
body = json.dumps({
"prompt": f"\n\nHuman: {user_prompt}\n\nAssistant:",
"max_tokens_to_sample": 100,
"temperature": 0.7,
"top_p": 1,
})
# 使用するモデルのID
model_id = 'anthropic.claude-v2'
accept = 'application/json'
content_type = 'application/json'
try:
# Bedrockのモデルを呼び出す
response = bedrock_runtime.invoke_model(
body=body,
modelId=model_id,
accept=accept,
contentType=content_type
)
# レスポンスから結果を抽出
response_body = json.loads(response.get('body').read())
ai_response = response_body.get('completion')
return {
'statusCode': 200,
'body': json.dumps({'response': ai_response})
}
except Exception as e:
print(e)
return {
'statusCode': 500,
'body': json.dumps({'error': str(e)})
}
コードを「Deploy」して、再度「Test」を実行してみてください。今度は、BedrockのAIモデルが生成した「AWS re:Invent」に関する説明が返ってくるはずです。やりましたね!これでAIと対話するプログラムが完成しました。
ステップ3: 実用的な応用
このままでは開発者しか使えないので、インターネット経由で誰でも呼び出せるように「API Gateway」というサービスと連携させます。API Gatewayは、Lambda関数のための「玄関」を作るサービスです。
- Lambda関数の画面で「トリガーを追加」をクリックします。
- ソースとして「API Gateway」を選択します。
- 「新しいAPIを作成」 > 「HTTP API」を選択します。
- セキュリティは「オープン」のままで、「追加」をクリックします。
これで、APIエンドポイントURLが生成されます。このURLにブラウザやツールでアクセスすると、Lambda関数が実行され、AIからの応答が返ってくるようになります。これで、あなたの作ったAIチャットボットが世界に公開されました!
ステップ4: チーム開発を意識した改善
今のコードは動きますが、実際の開発では保守性や共同作業のしやすさが重要です。いくつか改善してみましょう。
- IAM権限の最小化:
AmazonBedrockFullAccessは強力すぎます。実際の開発では、bedrock:InvokeModelのように、本当に必要なアクションだけを許可するカスタムIAMポリシーを作成します。 - ハードコーディングを避ける: コード内に直接書き込まれた
model_idやregion_nameは、後で変更するのが大変です。これらはLambdaの「環境変数」として外に出すことで、コードを変更せずに設定を変えられるようになります。 - エラーハンドリングの強化: 現在の
try-exceptブロックは単純です。どのようなエラーが発生したかを具体的にログに出力(printではなくloggingライブラリを使うのが望ましい)することで、問題解決が迅速になります。
これらの改善は、一人よがりではない、チームで開発するための大切な一歩です。
実際の開発現場での活用
私たちが作ったシンプルなAIチャットボットは、実際の業務でどのように活かせるのでしょうか。
業務での使用例
- 社内ナレッジ検索: 社内ドキュメントを学習させたAIモデルを使い、自然言語で質問すると関連箇所を要約して教えてくれるシステム。
- 顧客サポートの一次対応: よくある質問に対してAIが自動で回答し、複雑な問い合わせのみ人間のオペレーターに繋ぐチャットボット。
- コードレビュー支援: プログラムコードを送信すると、バグの可能性や改善点を指摘してくれる開発支援ツール。
このように、サーバーレスと生成AIの組み合わせは、アイデア次第で様々な業務の効率化に応用できます。
チーム開発でのベストプラクティス
チームでAWSを使った開発を進めるなら、Infrastructure as Code (IaC) の導入は必須です。AWS SAMやAWS CDKといったツールを使うと、今回手動で作成したLambda関数やAPI Gateway、IAMロールなどを全てコードで定義できます。これにより、「誰がいつ何を変更したか」がGitで管理でき、環境の再現やレビューが容易になります。
保守性を意識した書き方
- 単一責任の原則: 1つのLambda関数には1つの役割だけを持たせましょう。AIとの対話、データの保存、ユーザー認証など、機能ごとにLambda関数を分割することで、見通しが良く、改修しやすいシステムになります。
- ロギングとモニタリング: 何か問題が起きた時に原因を追跡できるよう、Amazon CloudWatchに適切なログを出力しましょう。「誰が」「いつ」「何をしようとして」「どうなったか」が分かるログは、システムの保守に不可欠です。
よくあるつまずきポイントと解決策
開発に失敗はつきものです。大切なのは、エラーから学び、次に進む力です。
初心者が陥りやすい問題
- IAMの権限不足: 最もよく遭遇するエラーです。
AccessDeniedExceptionというエラーが出たら、まずはLambdaの実行ロールに必要な権限(ポリシー)がアタッチされているかを確認しましょう。 - タイムアウトエラー: Lambda関数には実行時間の制限(デフォルトは3秒)があります。AIの応答が遅い場合など、処理に時間がかかりすぎるとタイムアウトします。Lambdaの「設定」 > 「一般設定」からタイムアウト値を延長できます。
- API Gatewayの設定ミス: APIを叩いても
Internal Server Errorが返る場合、API GatewayとLambdaの連携がうまくいっていない可能性があります。API GatewayのログやLambdaの実行ログを確認しましょう。
エラーメッセージの読み方
エラーメッセージは、問題解決のための最大のヒントです。焦らずにじっくり読みましょう。特に、Amazon CloudWatch LogsにはLambda関数の実行ログが全て記録されています。エラーが発生したら、まずは該当するロググループを探し、エラーメッセージやスタックトレースを確認する癖をつけましょう。
デバッグの基本的な考え方
「動かない!」とパニックになる前に、まずは問題を切り分けましょう。
- Lambda関数単体でテストは成功するか? (API Gatewayの問題かLambdaの問題か)
- コードのどの部分でエラーが出ているか? (
print文などを挟んで変数の内容を確認する) - 期待通りのデータが渡ってきているか? (Lambdaに渡される
eventオブジェクトの中身を確認する)
このように、原因の範囲を少しずつ狭めていくのがデバッグの基本です。
継続的な学習のために
今回の実践は、広大なAWSの世界への入り口に過ぎません。ここからさらに学びを深めていきましょう。
次に学ぶべきこと
- Amazon S3: ファイルやデータを保存するためのストレージサービス。あらゆるサービスの基本となります。
- Amazon DynamoDB: 高速でスケーラブルなNoSQLデータベース。サーバーレスアプリケーションと非常に相性が良いです。
- AWS Step Functions: 複数のLambda関数を組み合わせて、複雑なワークフローを構築するためのサービス。マイクロサービスの連携に役立ちます。
おすすめの学習リソース
AWSには、公式のドキュメントやチュートリアル、技術ブログなど、質の高い学習リソースが豊富に用意されています。特に公式ドキュメントは、サービスの正確な仕様を理解するための最も信頼できる情報源です。また、多くのクラウド学習サイトでハンズオン形式のコースが提供されているので、手を動かしながら学ぶのも良いでしょう。
コミュニティとの関わり方
一人で学び続けるのは大変ですが、同じ目標を持つ仲間がいれば心強いです。地域のユーザーグループが主催する勉強会や、オンラインの技術コミュニティに参加してみましょう。他の人がどんなことに挑戦し、どんなことでつまずいているのかを知ることは、自分の学習の大きな刺激になります。質問したり、自分の学びをアウトプットしたりすることで、知識はより深く定着します。
まとめ:成長のための次のステップ
お疲れ様でした!この記事では、来るべきAWS re:Invent 2024の予習として、技術トレンドの中心である「生成AI」と「サーバーレス」の基本を学び、実際に手を動かして簡単なAIチャットボットAPIを構築しました。
- クラウドの基本とAWSの環境構築を理解した。
- サーバーレスと生成AIの強力な組み合わせの概念を学んだ。
- AWS Lambda、Amazon Bedrock、API Gatewayを連携させ、動くアプリケーションを作った。
- チーム開発や保守性といった、実務で役立つ視点に触れた。
あなたはもう、re:Inventで発表される新しいサービスのニュースを聞いても、「これはあの技術の応用だな」「自分のアプリケーションにも使えるかもしれない」と、一段深いレベルで理解できるはずです。技術は常に進化し続けます。大切なのは、今日の成功に満足せず、好奇心を持って学び続ける姿勢です。今回の小さな成功体験をバネにして、ぜひ次のステップに進んでください。あなたのエンジニアとしての旅を、心から応援しています!


